如今,大语言模型如 ChatGPT 已在人们的生产生活中产生广泛影响。作为训练大语言模型的关键步骤,RLHF(Reinforcement Learning from Human Feedback)是一种利用强化学习方法从人类反馈中学习的技术。借助 RLHF 技术,大语言模型可与人类偏好保持对齐并遵循人类意图,满足 “有帮助的”、“诚实的” 和 “无害的” 的 3H(Helpful, Honest, Harmless)标准。然而,当前开源社区中复现 RLHF 技术仍具有较大挑战性,相关研究逐渐走向封闭。尚未有团队公开复现 RLHF 所需的数据、代码基准和验证流程,这极大地阻碍了 RLHF 科研的发展。
另一方面,尽管大语言模型的巨大成功得益于 RLHF 技术,但同时也面临着该技术带来的诸多问题。在 RLHF 中,标注员对大语言模型产生的回答进行偏好性打分,通过这些打分形成的偏序关系来训练模型。然而,由于人们的价值观、世界观存在差异,以及每个人所处地域文化、语言、习俗的不同,这些差异在标注过程中可能产生偏见和歧视性数据,导致目前依赖 RLHF 技术取得巨大成功的大语言模型也存在潜在的不安全问题。
为解决上述两个难题,北京大学团队开源了名为 PKU-Beaver(河狸)项目,其开源地址为:https://github.com/PKU-Alignment/safe-rlhf。
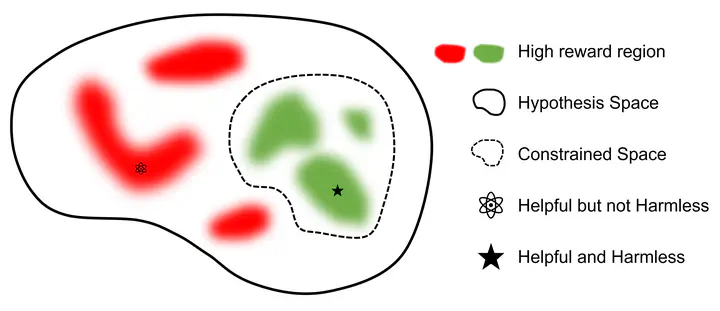
该项目首次公开了 RLHF 所需的数据集、训练和验证代码,是目前首个开源的可复现的 RLHF 基准。同时,为解决人类标注产生的偏见和歧视等不安全因素,北京大学团队首次提出了带有约束的价值对齐技术 CVA(Constrained Value Alignment)。该技术通过对标注信息进行细粒度划分,并结合带约束的安全强化学习方法,显著降低了模型的偏见和歧视,提高了模型的安全性。Beaver 使用 GPT4 进行 Evaluation,结果表明,在原有性能保持不变的情况下,Beaver 回复的安全性大幅度提升。